爬取网站注册用户和操作涉及到数据抓取和用户隐私保护的问题,需要谨慎处理。在进行此类操作时,请确保遵守相关法律法规和网站的爬虫政策,尊重用户隐私和数据权益。下面是一个基本的步骤指南,帮助你了解如何进行爬取操作。
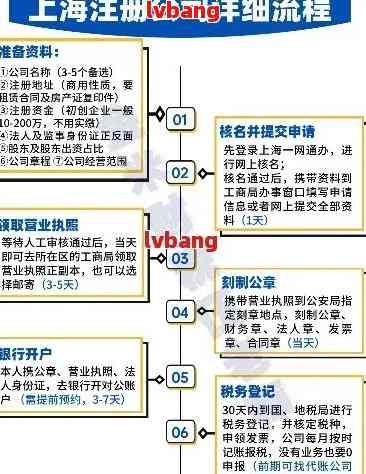
1、了解目标网站的结构和技术:你需要了解目标网站的结构和技术栈,包括使用的编程语言、数据库结构等,这将有助于你理解如何抓取数据。
2、获取网站数据:使用爬虫程序获取目标网站的数据,爬虫程序可以通过模拟浏览器访问网页,获取网页的HTML代码,并从中提取所需的数据,你可以使用各种编程语言和库来实现爬虫程序,如Python的Scrapy框架等。

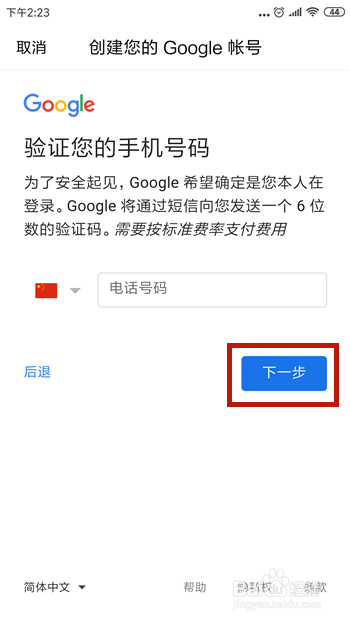
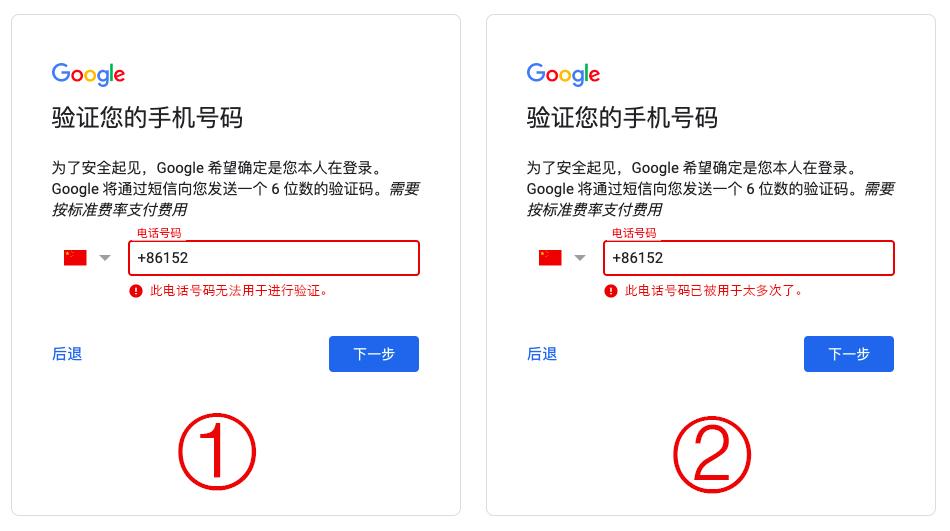
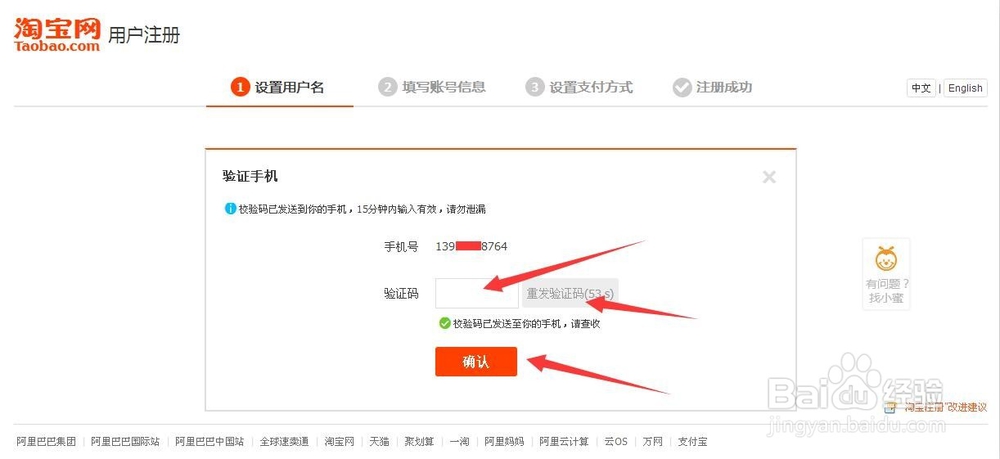
3、注册用户信息爬取:如果目标网站允许用户注册账户,你可以尝试模拟用户注册过程并爬取注册用户的信息,这通常涉及到填写注册表单并提交,然后抓取注册成功后的页面数据,某些网站可能有反爬虫机制,需要绕过这些机制才能成功获取数据。
4、操作爬取:除了注册用户信息外,你还可以尝试模拟用户操作,如登录、浏览页面、执行特定任务等,这需要更复杂的爬虫逻辑,可能需要处理会话管理、Cookie等。
5、数据处理和存储:获取的数据需要进行处理和存储,你可以使用Python的Pandas库来处理数据,并将其存储在数据库或文件中。

6、遵守法律和道德准则:在进行爬取操作时,请遵守相关法律法规和道德准则,尊重网站的数据政策、隐私政策等,不要进行非法爬取、侵犯用户隐私等行为。
爬取网站数据涉及到许多技术和法律问题,建议在进行此类操作前咨询专业人士的意见,并确保你的行为合法合规。